DQL query
Fetching data with Dgraph Query Language (DQL), is done through DQL Queries. Adding, modifying or deleting data is done through DQL Mutations.
This overview explains the structure of DQL Queries and provides links to the appropriate DQL reference documentation.
DQL query structure
DQL is declarative, which means that queries return a response back in a similar shape to the query. It gives the client application the control of what it gets: the request return exactly what you ask for, nothing less and nothing more. In this, DQL is similar to GraphQL from which it is inspired.
A DQL query finds nodes based on search criteria, matches patterns in the graph and returns the node attributes, relationships specified in the query.
A DQL query has
- an optional parameterization, ie a name and a list of parameters
- an opening curly bracket
- at least one query block, but can contain many blocks
- optional var blocks
- a closing curly bracket
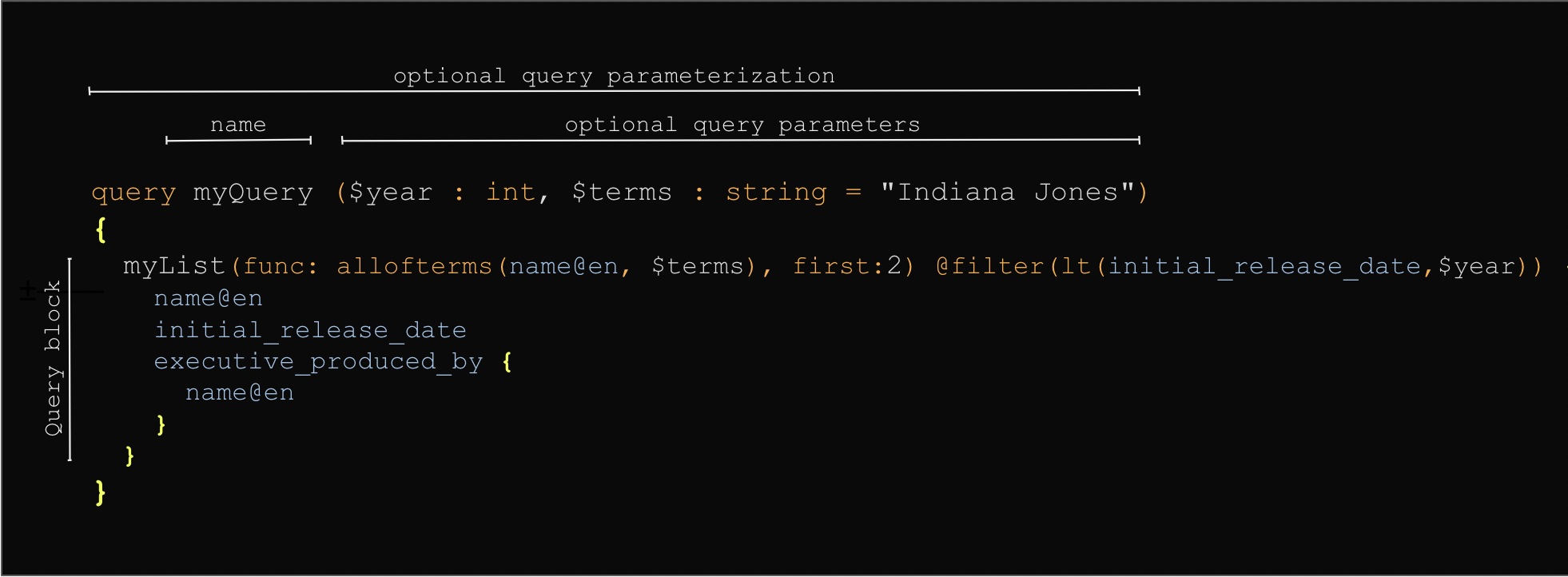
Query parameterization
Parameters
- must have a name starting with a
$symbol. - must have a type
int,float,boolorstring. - may have a default value. In the example below,
$agehas a default value of95 - may be mandatory by suffixing the type with a
!. Mandatory parameters can’t have a default value.
Variables can be used in the query where a string, float, int or bool value are needed.
You can also use a variable holding uids by using a string variable and by providing the value as a quoted list in square brackets:
query title($uidsParam: string = "[0x1, 0x2, 0x3]") { ... }.
Error handling When submitting a query using parameters, Dgraph responds with errors if
- A parameter value is not parsable to the given type.
- The query is using a parameter that is not declared.
- A mandatory parameter is not provided
The query parameterization is optional. If you don’t use parameters you can omit it and send only the query blocks.
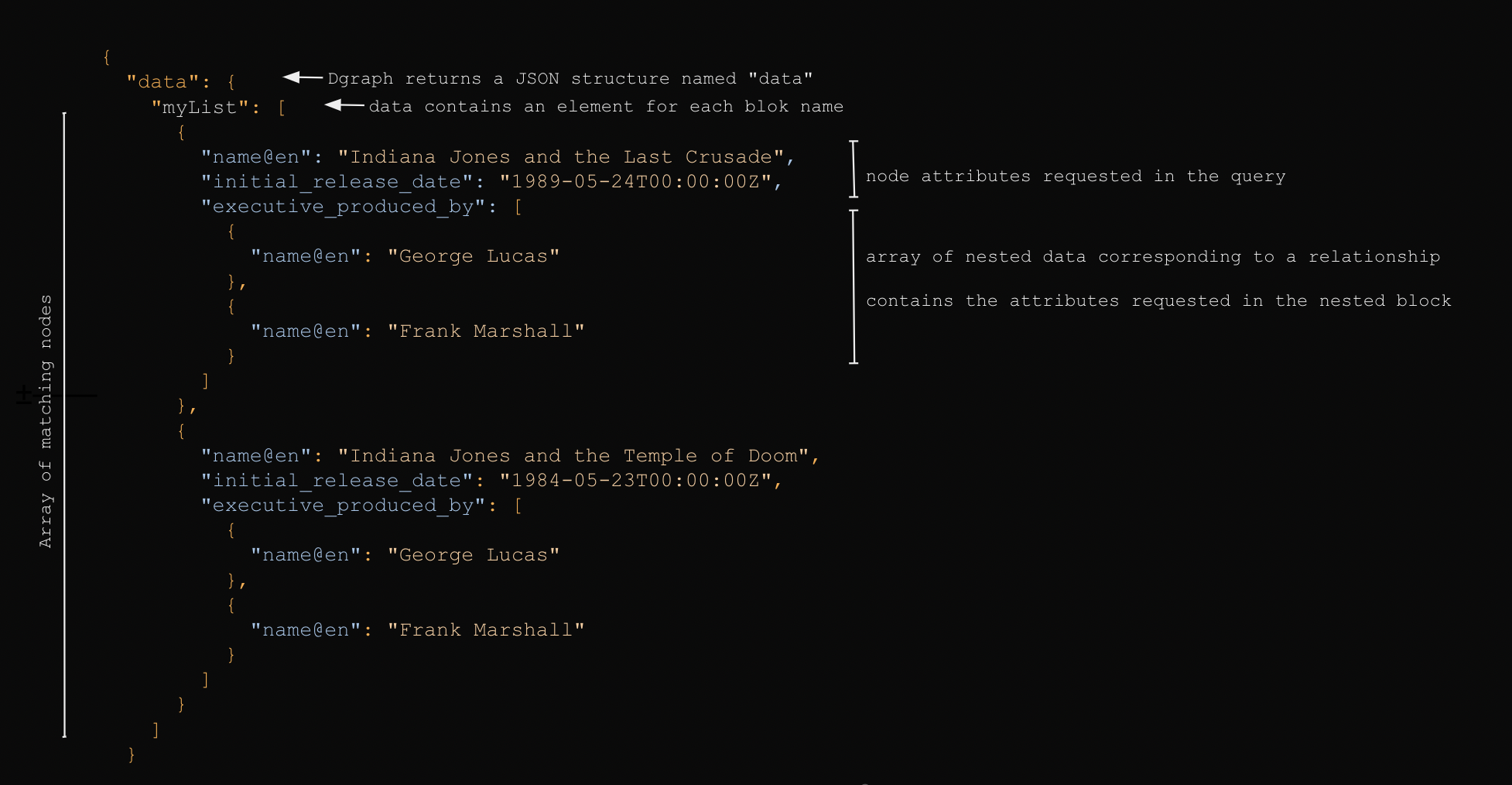
If you execute this query in our Movies demo database you can see that Dgraph will return a JSON structure similar to the request :
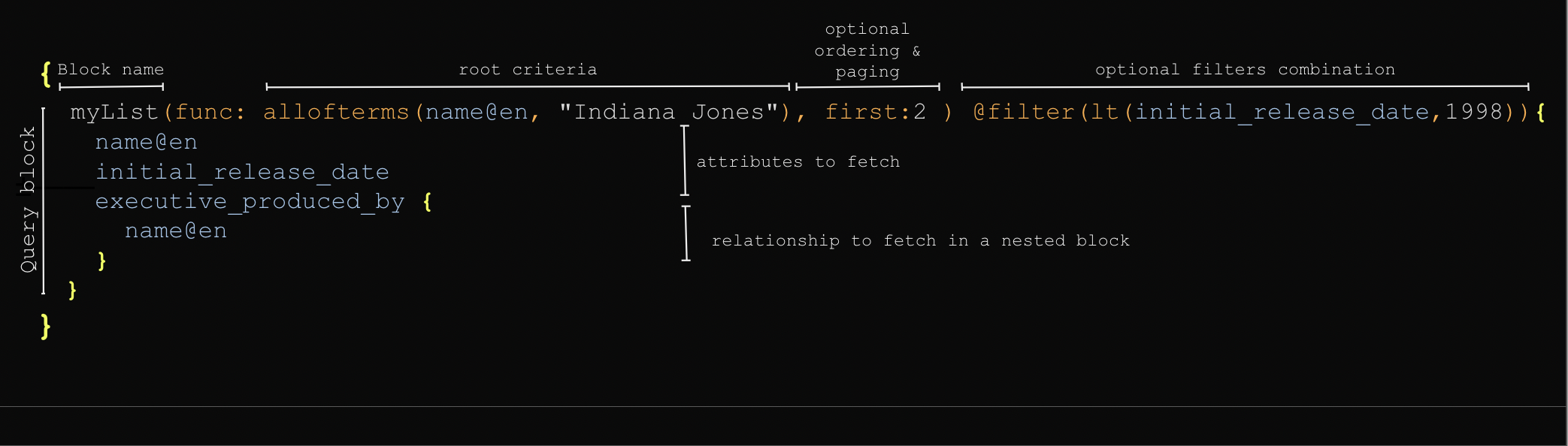
Query block
A query block specifies information to retrieve from Dgraph.
A query block
- must have name
- must have a node criteria defined by the keyword
func: - may have ordering and pagination information
- may have a combination of filters (to apply to the root nodes)
- must provide the list of attributes and relationships to fetch for each node matching the root nodes.
Refer to pagination, ordering, connecting filters for more information.
For each relationships to fetch, the query is using a nested block.
A nested block
- may specify filters to apply on the related nodes
- may specify criteria on the relationships attributes using filtering on facets)
- provides the list of relationship attributes (facets)) to fetch.
- provides the list of attributes and relationships to fetch for the related nodes.
A nested block may contain another nested block, and such at any level.
Formating options
Dgraph returns the attributes and relationships that you specified in the query. You can specify an alternate name for the result by using aliases.
You can flatten the response structure at any level using @normalize directive.
Entering the list of all the attributes you want to fetch could be fastidious for large queries or repeating blocks : you may take advantage of fragments and the expand function.
Node criteria (used by root function or by filter)
Root criteria and filters are using functions applied to nodes attributes or variables.
Dgraph offers functions for
- testing string attributes
- term matching : allofterms ,anyofterms
- regular Expression : regexp
- fuzzy match : match
- full-text search : alloftext
- testing attribute value
- equality : eq
- inequalities : le,lt,ge,gt
- range : between
- testing if a node
- testing the number of node relationships
- equality : eq
- inequalities : le,lt,ge,gt
- testing geolocation attributes
- if geo location is within distance : near
- if geo location lies within a given area : within
- if geo area contains a given location : contains
- if geo area intersects a given are : intersects
Variable (var) block
Variable blocks (var blocks) start with the keyword var instead of a block name.
var blocks are not reflected in the query result. They are used to compute query-variables which are lists of node UIDs, or value-variables which are maps from node UIDs to the corresponding scalar values.
Note that query-variables and value-variables can also be computed in query blocks. In that case, the query block is used to fetch and return data, and to define some variables which must be used in other blocks of the same query.
Variables may be used as functions parameters in filters or root criteria in other blocks.
Summarizing functions
When dealing with array attributes or with relationships to many node, the query may use summary functions count , min, max, avg or sum.
The query may also contain mathematical functions on value variables.
Summary functions can be used in conjunction with @grouby directive to create aggregated value variables.
The query may contain anonymous block to return computed values. Anonymous block don’t have a root criteria as they are not used to search for nodes but only to returned computed values.
Graph traversal
When you specify nested blocks and filters you basically describe a way to traverse the graph.
@recurse and @ignorereflex are directives used to optionally configure the graph traversal.
Pattern matching
Queries with nested blocks with filters may be turned into pattern matching using @cascade directive : nodes that don’t have all attributes and all relationships specified in the query at any sub level are not considered in the result. So only nodes “matching” the complete query structure are returned.
Graph algorithms
The query can ask for the shortest path between a source (from) node and destination (to) node using the shortest query block.
Comments
Anything on a line following a # is a comment